Hallo,
der Übersichtlichkeit halber eröffne ich ein neues Thema, die ursprüngliche Diskussion findet sich hier:
http://www.astrotreff.de/topic.asp?TOPIC_ID=209275
<b>Um was geht es?</b>
In der ernsthaften Messtechnik bekommt jedes Messergebnis seine Fehlerschranken zugewiesen. Oder wenigstens eine Angabe zur Messunsicherheit.
Bei der Vermessung von Optiken fehlt diese Angabe bisher, obwohl jeder Spiegelschleifer schon ein gutes "Gefühl" für die Genauigkeit des eigenen Prüflings entwickeln kann.
Jetzt ist klar, dass ein Prüfling zB in Form eines Spiegels eine eindeutig definierte Oberfläche hat, der sogenannte "wahre Wert".
Diese ändert sich kurzzeitig (Sekunde bis Minuten) nicht.
Langzeitig kann es durchaus zu kleineren Schwankungen kommen (Thermik), dieser Einfluss soll jetzt unberücksicht bleiben.
Sinn einer Messung ist es, die Form der Oberfläche von sämtlichen "Drecks-Effekten" wie Messfehler, Bildrauschen, Luftschlieren zu bereinigen. Das gelingt am besten mit statistischen Methoden und vielen Messwerten.
Sinn der <b>Fehlerschranke</b> ist es, ein Intervall anzugeben, in dem sich der "wahre Wert" <b>sicher</b> befindet.
Sinn der <b>Messunsicherheits-Angabe</b> ist es, ein Intervall anzugeben, in dem sich er "wahre Wert" <b>wahrscheinlich</b> befindet.
<u>Beispiel: Durchmesser von Kugellagerkugeln</u>
Wenn man Kugeln mit dem Durchmesser 10mm braucht, die maximal 0.1mm größer oder kleiner sein dürfen, kann man folgendes machen:
Man bohrt zwei Löcher mit 9.9mm und 10.1mm.
Wer durch das erste Loch fällt ist zu klein.
Wer am zweiten Loch hängenbleibt ist zu groß.
Diesen Luxus von festen Fehlerschranken hat man bei Optiken meistens nicht.
Dazu müssen, wie im Kugelbeispiel, die Löcher <b>wesentlich</b> genauer gemessen werden, wie die benötigten Fehlerschranken.
Deshalb behilft man sich statistischer Methoden und grenzt den Fehler "unscharf" ein.
Die Angabe der <b>Messunsicherheit</b> (in Form von Sigma) bedeutet, dass sich der wahre Wert mit <b>68% Wahrscheinlichkeit</b> in dem Intervall +/- Sigma befindet. Im Intervall +/- 2*Sigma sind es 95%.
<u>Beispiel: Spiegel mit RMS surface 8,5nm und Sigma 0.39nm</u>
Umgerechnet auf Strehl bedeutet das, das 2-Sigma Intervall liegt zwischen Strehl 0,956 und 0,969.
In einen von 20 Protokollen dieser Art würde man eine Optik vor sich haben, die in Wirklichkeit schlechter oder besser ist.
Ja, auch besser kann passieren. Luftschlieren können theoretisch ein Protokoll mit Strehl 0,99 erzeugen, bei einen Spiegel mit "wahem Wert" von 0,80 Strehl!
Doch dieses Ereignis ist <b>extrem selten</b> - selbstverständlich kann man mit der Kenntnis von Sigma auch diese Chance berechnen.
Üblicherweise wird als Messunsicherheit das 1-Sigma-Intervall angegeben. In zwei von drei Protokollen würde der wahre Wert im +/-Sigma Intervall liegen.
<b>Jetzt zur eigentlichen Rechnung</b>
Vor zwei Jahren habe ich mir schon mal den Kopf über das Problem zerbrochen, zusammen mit einem Spiegelschleifer-Kollegen.
Schnell wurde klar, dass die Suche nach "fertiger Arbeit" die bessere Alternative dastellt.
Der beste Artikel zu dem Thema ist leider nur käuflich zu erwerben.
Er trägt den Titel:
<b>Estimating the root mean square of a wave front and its uncertainty</b>
Angela Davies and Mark S. Levenson
1 December 2001 / Vol. 40, No. 34 / APPLIED OPTICS 6209
Leider sehe ich keine Möglichkeit, den Inhalt des Artikels frei zugänglich zu machen.
Findet jemand einen Download?
Jetzt habe ich mich um eine Umsetzung bemüht und will nicht arantieren, dass alles richtig ist.
Ziel war es, mit den Möglichkeiten von OpenFringe auszukommen, ohne dass der Autor des Programms Dale Eason irgendwelche schnittstellen programieren muss.
Um eine Datenbasis von 30 Messungen hat sich Kurt gekümmert - besten Dank Kurt!
Das sind die Daten die Kurt geliefert hat:
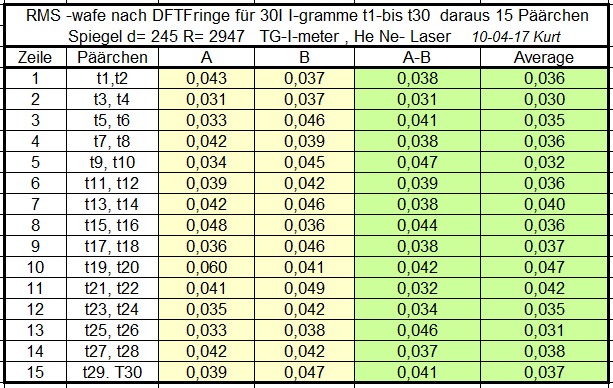
Aus den 30 Wavefronten sind <b>zufällig</b> Paare zu bilden.
Von diesen 15 Paaren wird jeweil die Differenz und die Summe benötigt, und zwar <b>punktweise</b>
Differenz ist in OpenFringe die Funktion "A-B".
Summe gibt es nicht direkt, deshalb verwende ich "Average" und multiplizere mit zwei.
Als <b>Input</b> braucht es also den <b>Wavefront-RMS</b> von <b>Differenz</b> und <b>Average</b>.
Schema V2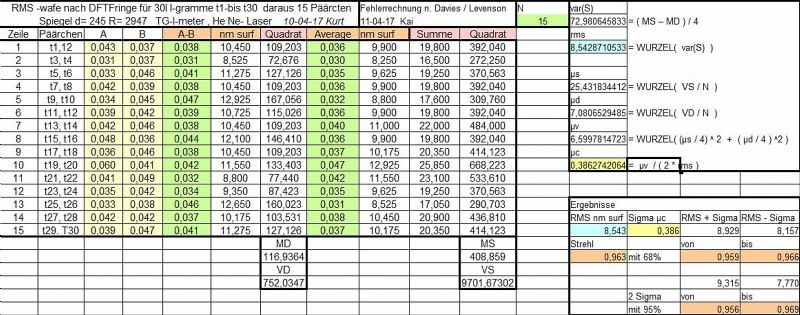
Die Umsetzung des Artikels verlangt weitere Hilfgrößen, u.a. wird zunächst im Quadrat des RMS (=Varianz) und in der Einheit "nm surface" gerechnet.
Im linken oberen Kasten sind die Hilsrechnungen kommentiert.
Nein, es sind keine komplizierten Operationen dabei.
Die Umrechnung in Strehl als abgeleitete Größe erfolgt erst ganz am Ende.
<b>Achtung:</b>
Der angezeigte RMS bzw Strehl 0.963 ist <b>ausschließlich</b> aus den Summen und Differenzen errechnet!
Wenn Kurt den "Average" aus den 30 Wavefronten gebildet hat, bin ich auf die Übereinstimmung schon sehr gespannt!
Das würde die Richtigkeit des Verfahrens stützen.
Im Moment ist mein Chart auf fixe 15 Paare limitiert.
Das ergibt eine überraschend kleine Messunsicherheit.
Liegt an Kurt's hochwertigen Interferogrammen - natürlich ist es Messunsicherheit, welche die Qualität einer Messung wiederspiegelt, und nicht das Messergebnis selbst [;)]
Man kann die Messunsicherheit noch weiter senken, wenn man die Anzahl der Paare erhöht.
<b>Viermal</b> mehr Messungen, 60 Paare statt 15, würden die Messunsicherheit von 0.386nm auf 0.193 <b>halbieren</b>.
Für die mittlerweile übliche Rotation des Prüflings wird sicher noch eine Lösung gefunden.
Für kleinere Optiken, an die zu recht besondere Anforderungen gestellt werden, sollte es erst einmal reichen.
Fragen, Hinweise, Kritik immer gern.
Für einen Review des Artikels durch interessiertes Fachpersonal wird sicher noch eine Lösung gefunden werden.[;)]
Viele Grüße
Kai
edit: Schema V2 korrigiert